基本信息
- 标题: AGILE CODER: Dynamic Collaborative Agents for Software Development based on Agile Methodology
- 作者: Minh Huynh Nguyen、Thang Chau Phan、Phong X. Nguyen、Nghi D. Q. Bui(通讯作者)
- 作者单位: FPT Software AI Center、Fulbright University
- 期刊/会议: FORGE(ICSE) 2025
- 发表年份: 2025.07.02
- DOI: 10.1109/Forge66646.2025.00026
- 开源地址: Github
- 关键词: Software Development, Multi-Agent System, Large Language Models
研究问题 (Research Questions)
解决仓库级别的代码生成问题
研究背景 (Background)
专业软件开发的敏捷方法
敏捷源自敏捷宣言 [agi, 2001],是一种灵活的软件开发方法,强调交付最终产品的实用主义。它促进持续交付、客户协作以及快速适应不断变化的需求。与瀑布模型等传统线性方法不同,敏捷通过Sprint(短周期)采用迭代开发,可以快速调整和频繁重新评估项目目标。这种迭代方法增强了与客户需求的一致性,并促进团队内部的开放沟通和共同责任。敏捷的适应性使其对于管理需求可能随时间变化的复杂项目特别有效。通过将敏捷原则与软件开发中的协作代理相结合,我们为设计多代理系统提供了一种新颖的视角。
仓库级别的代码理解和生成
在存储库级别生成代码是现实世界软件工程任务中大型语言模型(llm)面临的重大挑战。现实世界的代码库是复杂的,具有相互连接的模块,并且随着上下文大小的增加,llm面临限制。这导致了选择相关上下文的研究并优化其使用。软件智能体,如ChatDev和MetaGPT,旨在生成功能齐全的可执行软件,包括各种文件,类和模块,而不仅仅是像HumanEval [Chen等人,2021]或MBPP [Austin等人,2021b]中简单任务的解决方案。这要求代理在生成代码或修复错误时理解所有现有上下文,包括文件、类、函数和库。然而,在以前的研究中,对全面的库级代码理解和生成的需求经常被忽视。
核心贡献 (Key Contributions)
- 引入了AgileCoder,是一种受到敏捷开发启发的新型多智能体软件开发框架,强调智能体之间的有效沟通和增量开发。
- 引入了动态代码图生成器(DCGG)将静态分析方法整合到多智能体工作流中,该生成起可以动态生成代码依赖图(CDG)。这个图会记录代码库的演变过程中各个代码组件之间的依赖关系,为智能体提供了一个可靠的来源以获取相关上下文信息,从而提高了生成工程的质量。评估结果显示,使用了CDG获取到的上下文信息,性能表现显著增长。
- 实验证明AgileCoder在HumanEval、MAPP上达到了SOTA,并提出了ProjectDev作为软件开发的Benchmark。在这个框架上,超越了MetaGPT和ChatDev。
方法 (Methodology)
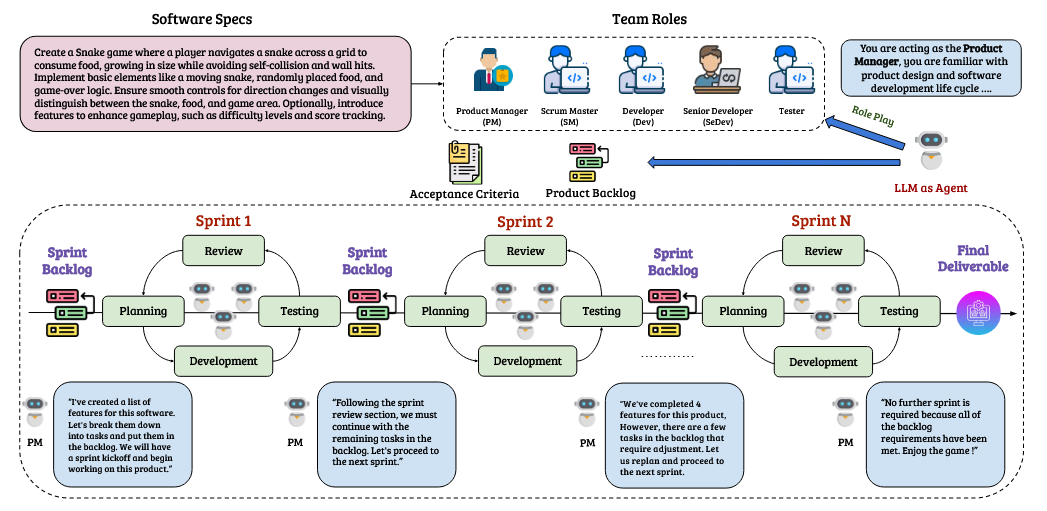
上图呈现了AgileCoder的总体框架,其中包括多个智能体:产品经理(PM, Product Manager)、敏捷开发负责人(SM, Scrum Master)、开发人员(Dev, Developer)、高级开发人员(SenDev, Senior Developer)和 测试人员(Tester), 各个智能体通过敏捷开发方式进行协作开发。开发过程包括执行环境(Execution Environment)以在测试期间运行代码,并有动态代码生成器(DCGG)在代码更新时动态生成代码依赖图(Code Dependency Graph)。执行环境(Execution Environment)为智能体提供回溯以进行代码优化,而DCGG使智能体能够获取相关上下文以准确地生成和修正代码。
智能体(Agent Roles)
每个智能体的角色定义如下所示:
- 产品经理(PM,Product Manager): 从用户这里获取需求并且创建待办清单(Backlog),其中包含开发任务和验收标准。
- 敏捷主管(SM,Scrum Master):向产品经理提供代办清单的反馈,以提高敏捷迭代(Sprint)的可实现性。
- 开发人员(Dev, Developer):主要专注于开发任务,包括生成代码和根据其他智能体的反馈进行重构代码。
- 高级开发人员(SenDev, Senior Developer):审查开发人员生成的代码,为代码重构提供反馈,确保质量控制。
- 测试人员(Tester):生成测试用例和脚本,以验证开发人员开发的代码。
工作流概览
整个工作流从产品经理(PM)在收到用户需求后启动代办事项(Backlog)计划开始。PM在backlog中编写任务和验收标准。敏捷主管(SM)会审查backlog,评估任务的可行性,并可能要求PM进行修订。输出结果是product backlog。一旦规划完成,SM就会用一个Sprint来启动开发,每个Sprint都包括规划、开发、测试和审查阶段。在规划期间,SM从product backlog中选择任务放入sprint backlog中。剩下的阶段涉及到子阶段,在子阶段里智能体协作完成任务。在所有阶段完成之后,SM会评估以确定软件是否已准备好交付。如果没有,下一个Sprint将从规划开始。重复此过程,直到SM决定软件可以交付,此时终止信号将结束开发流程。
规划阶段(Planning Phase)
在每个Sprint开始时,PM会指定计划,其中包含product backlog中选定的任务、定义的验收标准,以及从前一个Sprint的评审中获得的结果(如果适用的话)。SM会提供反馈以完善该计划,确保其与项目的当前目标和约束相符。这个阶段的产出时Sprint代办实现列表,概述了在冲刺阶段要完成的任务范围。
开发阶段(Development Phase)
在规划完成之后,PM会指示Dev开始实现。为了增强其他智能体的清晰度,要求Dev使用docstrings注释每个方法/函数。然而由于LLM的幻觉可能产生的不准确性,生成的代码可能并不总是与sprint backlog和验收标准相符。为了缓解这种情况,SenDev采用了一种受同行评审启发的静态审查过程,主要是找出明显的漏洞、逻辑错误和边界情况,并提供纠正反馈。审查过程被分成三个顺序步骤来管理复杂性并提高反馈效果。第一步涉及检查基本错误如空方法和缺失导入语句;第二部确保代码符合sprint backlog;最后一步确认代码满足验收标准且无漏洞。
测试阶段(Testing Phase)
尽管经过彻底的审查,但由于大语言模型的幻觉,不能保证没有错误的代码。因此,测试人员来编写测试用例并实施测试计划,向开发者提供实时反馈以迭代优化代码。
编写测试用例 在Sprint过程中,沿用了前几次的代码,并实现新的功能。虽然现有的代码经过了彻底的审查和测试,但新代码缺乏这样的审查,因此需要创建测试用例确保功能正确性。作者利用DCGG创建的代码图G和改变文件列表F来找出需要测试的文件。这个过程可以描述为 $\bigcup f(n_i) \cup \{n_i\}, n_i \in \mathcal{F}$,其中f返回节点在图G中的祖先节点。例如在下图中,如果user_manager.py文件发生任何变化,我们应该重新检查它以及祖先文件的功能正确性,但不包括user.py。然后由Tester负责编写所有必要的测试用例。
编写测试计划 在写完测试用例后,我们需要由多个测试脚本,必须按照特定的顺序执行,以避免代码文件不一致和不必要的成本。例如在下图中,user_manager.py文件依赖于user.py文件,因此在测试user.py之前测试user_manager.py时不合逻辑的。可以通过反转代码图G测试脚本的拓扑顺序来得到一个合理的测试计划。此外为了最终软件能够执行,所以需要Tester编写命令来评估其可执行性。
修复漏洞 一旦明确了测试计划,就会根据计划反复执行脚本,指导出现错误或失败的测试用例等问题。Dev根据Tester提供的测试报告处理这些问题,并重复此过程,指导完成测试计划。
审查阶段(Review Phase)
在Sprint的最后,Tester运行软件来写一个测试报告。然后PM收集sprint backlog、源代码和测试报告,以评估已完成、失败和未失败的任务。这些信息会随着sprint的进行而积累,形成一个总体报告。然后PM将这个总体报告与product backlog和验收标准进行比较,以决定是否结束任务或进行下一次sprint。如果结束SM编写详细的文档,包括如何运行和安装必要的库。如果计划另一次Sprint,则PM审查product backlog、验收标准和当前的总体报告来创建下一次冲刺计划。
用于上下文感知的动态图生成器
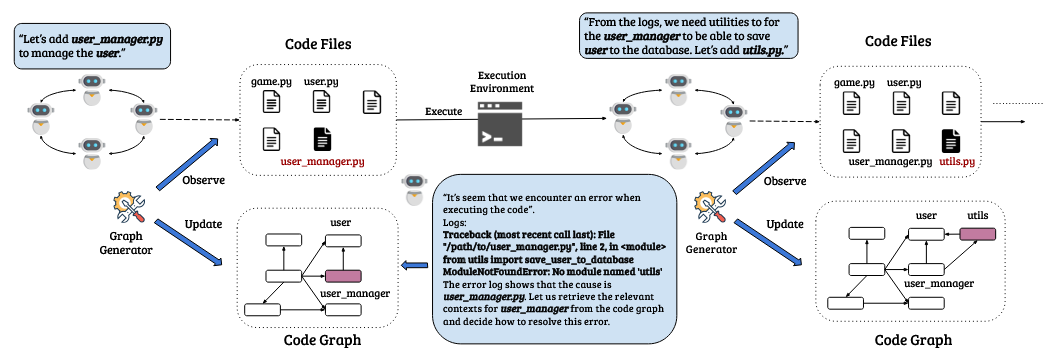
动态代码图生成器(DCGG, Dynamic Code Graph Generator)是系统中的一个关键模块,它可以动态创建和更新代码依赖图(表示为G)。该图有效地对代码文件之间的关系进行建模,从而促进高效的上下文感知代码检索。在G中,每个节点代表一个代码文件,每条边代表一个依赖关系。比如user_manager.py与user.py之间的关系如上图所示。主要捕获import关系以保持图的简单性和效率。随着代码库不断演变,无论通过添加新功能还是修正错误,G都会被更新以准确反映当前状态。这对于维护代码库的完整性并确保所有的更改都得到适当记录和集成至关重要。此外,在sprint期间修改的文件(标识为F),也会被记录并链接到G中以跟踪所有受影响的依赖项。总结来说,DCGG主要执行两个基本功能:
- 协助编写测试用例和测试计划:当生成新代码时,DDCG确保只有受影响的文件需要测试。而且,使用G总是可以获得合理的测试计划。
- 提供代码修复的上下文:当代码执行过程中出现错误时,智能体会通过回溯来分析识别相关文件。它从代码图中获取跨文件的上下文以确定错误源,确保有效地检索代码。
现有的方法,如ChatDev和MetaGPT所采用的方法,通常涉及将整个代码库加载到LLMs,但当代码库增长超过LLMs的token限制时,这种做法就变得不切实际。DCGG通过维护一个依赖关系图来解决这个限制问题,这个图运行智能体选择性地检索相关信息,从而优化了LLM的标记使用,并保持想Dev或其他智能体提供信息的相关性和准确性。
这种涉及方法不仅提高了代码生成和调试的效率,而且确保开发过程得以精简并集中,避免了无关数据的干扰,并增强了整个开发工作流程的准确性。上图展示了如何在代码库变化时更新DCGG,从而维持对代码结构最新、最准确的反映。
智能体之间的交流机制
系统在所有阶段都采用双智能体对话涉及,将交互模型简化为两个角色:导师和助理。这种结构避免了与多智能体拓扑相关的复杂性,并简化了共识过程。导师负责提供清晰的指导并引导对话流程向完成特定任务的方向进行,而助理则利用他们的技能和只是来执行任务,互相持续进行直至达成共识。
为了确保消息之间对话的连续性和连贯性,采用消息流S。这个流作用与工作记忆,存储所有交换过的消息,使智能体能够创建与会话历史无缝连接的回应。正式地说,如果$i_t$和$a_t$分别是在时间步骤t由导师和助理产生的信息,则$S_t = [(i_1, a_1), (i_2, a_2), ..., (i_t, a_t)]$
在下一此时间步t+1, 导师审查$S_t$以评估行动$a_t$与提供的指示之间的一致性,然后发出进一步的指示$i_(t+1)$。同时,助手在收到新的指示$i_(t+1)$后,制定适当的回应$a_(t+1)$,如果$a_(t+1)$满足终止标准或者互动达到预设交流限制,则对话结束。最后一条消息$a_(t+1)$被存储已备未来参考,确保保留和建设性信息。
交流协议 与之前的一些研究一致,本方法的交流接口采用无约束的自然语言。这种灵活性允许轻松修改提示词,例如调整输出约束或更改格式,而不会对系统产生重大影响。此外,AgileCoder在每次i对话的开时,采用一种名为提示词工程的技术,以优化理解和任务执行。这个初始设置确保双方都充分了解任务要求和目标,从而促进生成相关的响应,以成功完成任务。智能体将在达成共识之前自主进行,无需人工干预。
全局消息池 为了促进整个系统中的信息顺畅流动,共享环境中的全局消息池,存储所有的对话输出。该环节记录任务的状态(无论是已完成、待处理还是失败),为智能体做出明确的决策提供丰富的上下文。然而,考虑到信息量可能很大,直接将所有数据暴露给智能体可能会超出上下文限制。因此,每个对话只访问全局消息池中必要的、与任务解决相关的片段。例如,产品进来可能专注于product backlog和sprint计划中的任务状态,而dev可能主要需要访问与bug修复相关的特定代码部分。这种有针对性的访问策略可以防止上下文过长,并确保所有智能体都能够获得当前最相关的信息。
实验
Empirical Results
Dataset 为了评估,作者选择两种类型的数据集。
- 第一个包括评估CodeLLMs代码生成能力的知名benchmark:HumanEval和MBPP。这些benchmark主要包含竞赛问题,并不完全代表真实世界软件开发中的复杂性。
- 第二种,作者手机了14个更复杂的软件开发任务的代表性示例,统称为ProjectDev。这些任务覆盖了迷你游戏、图像处理算法和数据可视化等多种领域。每个任务都附带详细的提示,要求系统生成一个包含多个可执行文件的代码库。作者对每个任务运行三次并并去平均数。
Metrics 对于HumanEval和MBPP,作者采用无偏pass@k进行度量,遵循MetaGPT的方法来评估top-1生成代码的功能准确性。对于ProjectDev数据集,作者侧重于实际应用,并通过人工评估和统计分析来评估性能。人工评估包括根据预期需求检查生成的软件的可执行性,以确定满足这些需求的成功率(例如,如果生成的程序时可执行的,并且满足10个需求中的4个,则其可执行率为40%),并计算生成的程序无法运行时的总错误数(#errors)。统计分析包括运行时间、token使用频率、所用方法的费用以及仅针对AgileCoder平均Sprint次数等指标。
Baselines 作者才使用SOTA CodeLLMs作为基准,包括CodeGen、CodeGenX、PaLM Coder、DeepSeek-Coder、GPT-3.5、GPT-4和Claude 3 Haiku。鉴于AgileCoder是一个多智能体系统,作者还将其与用于软件开发任务的领先的多智能体系统进行了比较,例如MetaGPT和ChatDev。
Results
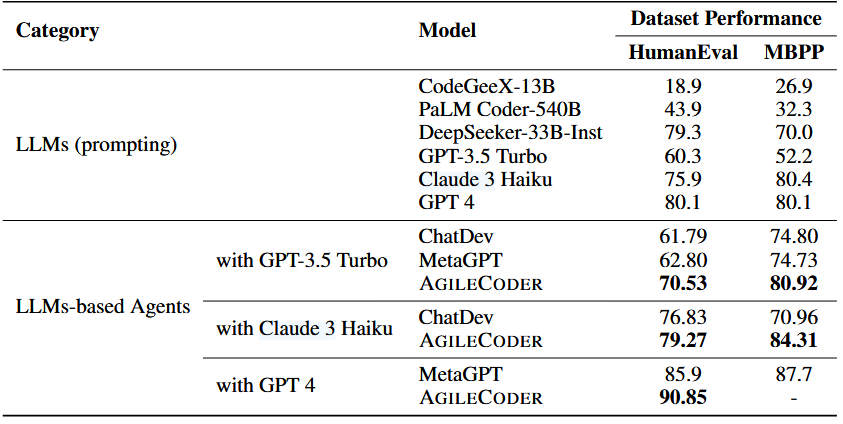
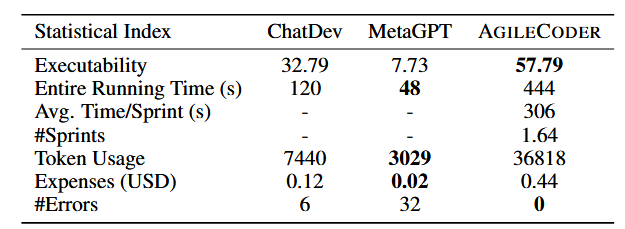
上表显示,AgileCoder在HumanEval和MBPP评估基准上显著由于最近的SOTA多智能体和CodeLLMs。AgileCoder在HumanEval上相对于ChatDev和MetaGPT的pass@1平均提升分别为5.58和6.33,在MBPP上也实现了类似提升。在ProjectDev上的结果如第二张表所示,进一步证明了AglieCoder在软件开发任务中的优势。AgileCoder相比ChatDev和MetaGPT,在可执行性方面有了显著提升,并且没有生成任何不可执行的程序。这些优势归因于AgileCoder融入了规划阶段、生成的测试用例以及高效的代码检索,而ChatDev和MetaGPT缺乏这些。尽管AgileCoder由于敏捷Scrum方法论固有的复杂性需要更多的token和运行时间,但他平均在1.64个sprint内高效地完成用户任务。
重要的是要承认,HumanEval和MBPP可能不是评估这种复杂性的多智能体最合适的基准,因为它们主要包含竞争性编程的简单问题,这也是之前工作中认识到的问题。因此,像ProjectDev这样的benchmark更适合于评估这些系统的性能。MetaGPT提供了一个类似的benchmark,名为SoftwareDev,ChatDev为同样的目的手工制作了一个名为软件需求描述数据集(SRDD)的基准测试。不幸的是,这两个基准都不是公开可用的。相比之下,我们的数据集将会公开发布,以促进该领域的开放研究。
Analysis

Sprints数量的影响 作者进行消融实验以评估增量开发的影响。增量开发涉及多个sprint,而消融实验压缩为单个sprint。上表表明,增量开发可以在两个模型上提高HumanEval和MBPP的性能。这一优势源于继承之前的Sprint的输出以进一步细化并解决后续迭代中的现有问题,从而增加成功结果的可能性。
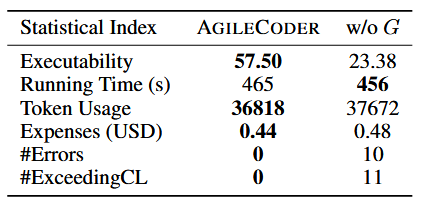
代码依赖图的影响 代码依赖图G在AgileCoder中起着至关重要的作用,如上表的结果所示。没有图G的AgileCoder变体容易出现超过上下文长度的错误,而AgileCoder本身不会遇到这个问题。值得注意的是,G的存在导致可执行性显著改善,从23.28%增加到57.50%。图G的缺失可能导致测试脚本之间的随机顺序,从而在错误修复过程中导致不一致。此外,忽略G意味着所有源代码总是包含在指令中,由于不相关的信息和增加的成本,可能会压倒甚至损害llm。
优点
- 引入敏捷开发模型
- 引入DCGG,生成依赖图